Исследовать поисковый спрос — обычная задача для SEO-специалиста: просто собираешь запросы, смотришь частотность, сезонность — и готово. Но что если нужно посмотреть на целый рынок, где представлено много брендов, а ваши сроки и ресурсы ограничены? Рассказываем.
Чтобы приготовить репрезентативный дашборд, вам понадобятся KeyCollector, пара библиотек в Python, ClickHouse или Google-таблицы и DataLens.
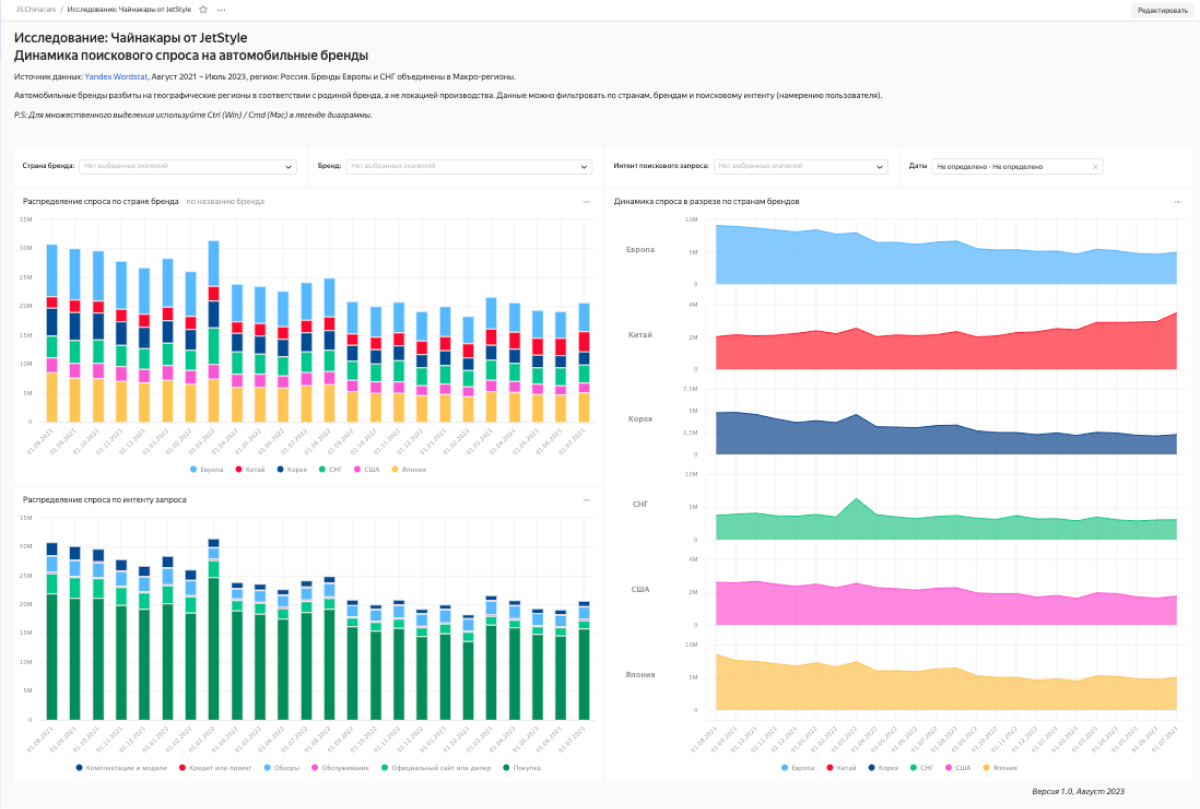
Мы в JetStyle исследуем китайский авторынок в РФ и для оценки спроса решили посмотреть на данные поисковиков, чтобы понять, как меняется интерес к разным маркам и производителям. Сначала мы подошли к этой задаче стандартно: взяли список всех брендов, официально представленных в России, и собрали статистику запросов по ним за два года из Вордстата. Но поняли, что эти данные без интентов нам ни о чем не говорят. Поэтому нам пришлось усложнить себе задачу, собрать еще больше данных, а потом автоматизировать их обработку и визуализировать с помощью Python, ClickHouse и DataLens. Дальше по шагам.

Первый подход
1. Собираем список брендов и синонимов
Список всех автомобильных брендов мы собрали в двух написаниях — на английском и русском, с учетом вариаций. Ведь если к «европейцам» все уже привыкли, то с «китайцами» сложнее — чего стоит написать бренд KAIYI по-русски, словоформ может быть несколько. Мы придумывали их сами и с помощью поисковых подсказок Яндекса, а потом проверяли в Вордстате, действительно ли реальные пользователи так пишут.
2. Собираем данные с запросами по каждому бренду с учетом сезонности
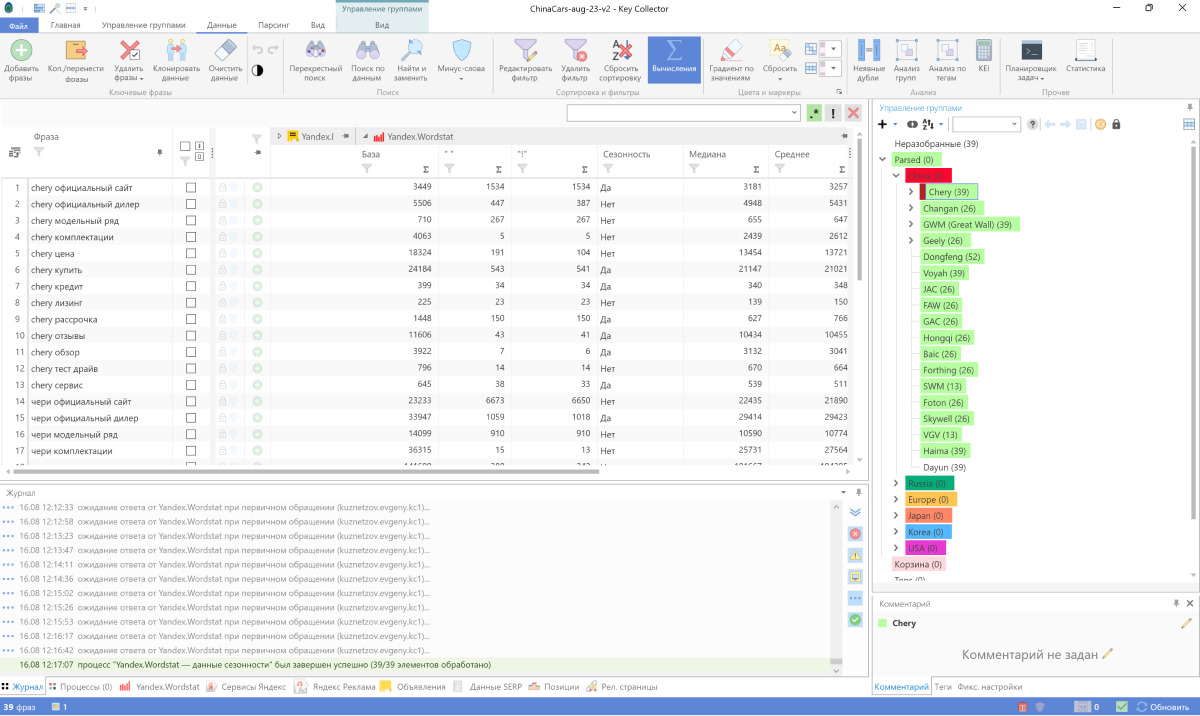
Загрузили получившийся список в KeyCollector и собрали сезонности по России.
Если вам интересны технические подробности — посмотрите видео SEO-специалиста Александра Ожгибесова:
На выходе KeyCollector выдал нам CSV-файл со списком релевантных запросов и популярностью по месяцам.
3. Переносим CSV в Google-таблицы
Для удобства работы с данными и их визуализации мы привели таблицу к «длинному» виду. А также обогатили данными — унифицировали название бренда для разных словоформ и добавили страну бренда.
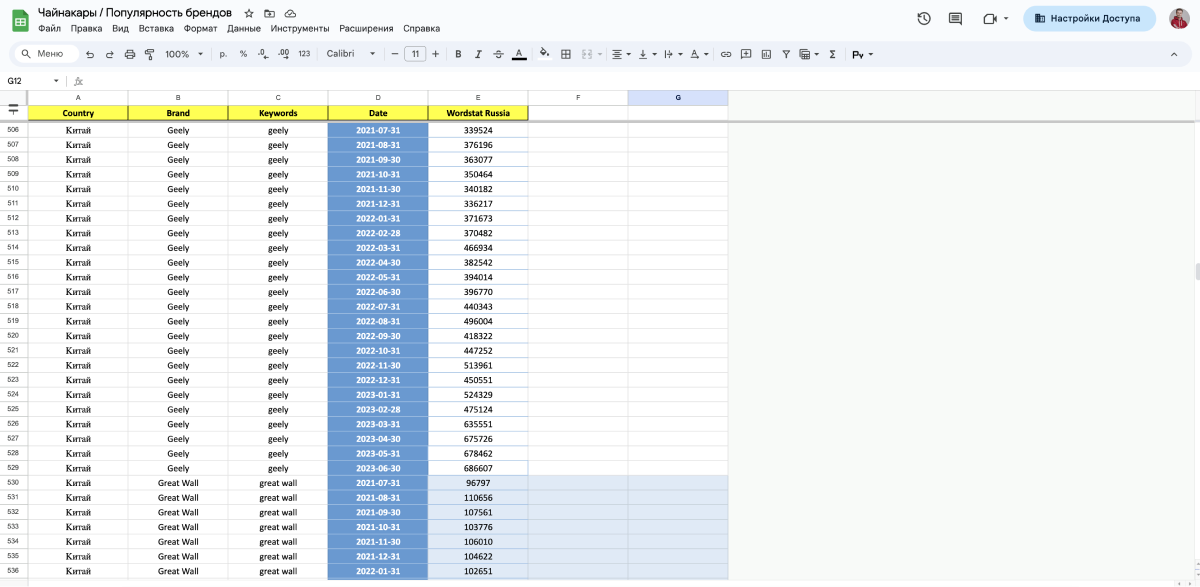
4. Визуализируем результат
Подключаем Google-таблицы к DataLens, чтобы анализировать данные на графиках, а не в табличном виде.
5. Строим первый чарт и…
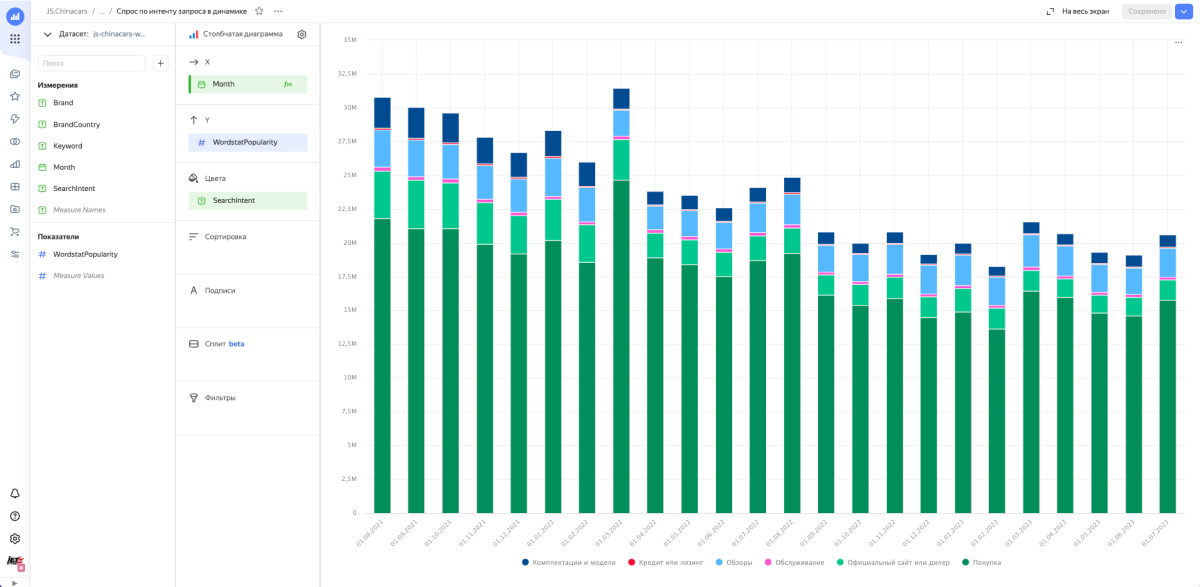
Получаем много мусора. Картина смазанная и не видно динамики, как китайцы вытесняют европейцев, корейцев и японцев — хотя, казалось бы, она очевидна. Мы видим это на улицах и в рекламе, но не в наших данных. Почему? Потому что в этом подходе мы не учитываем интент поискового запроса, а смотрим просто все бренды в общем.
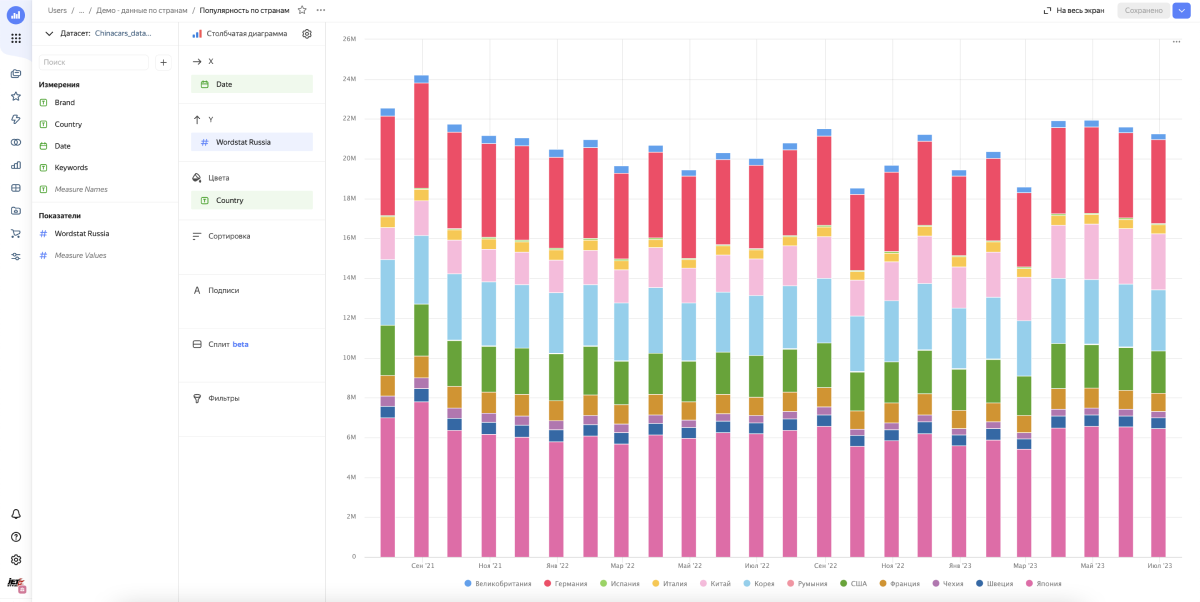
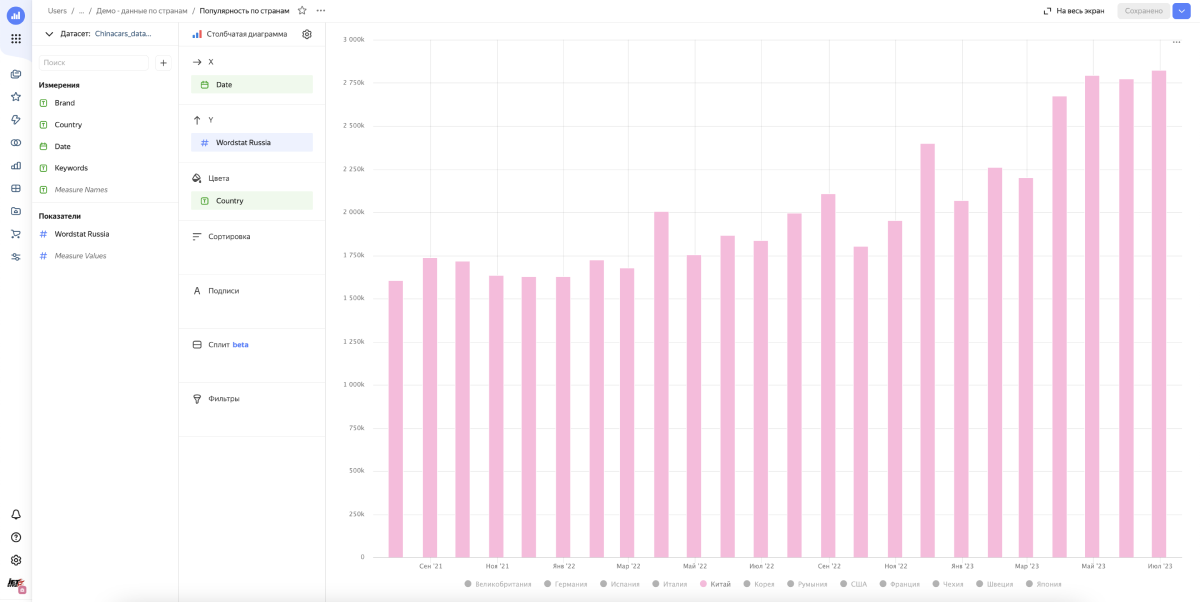
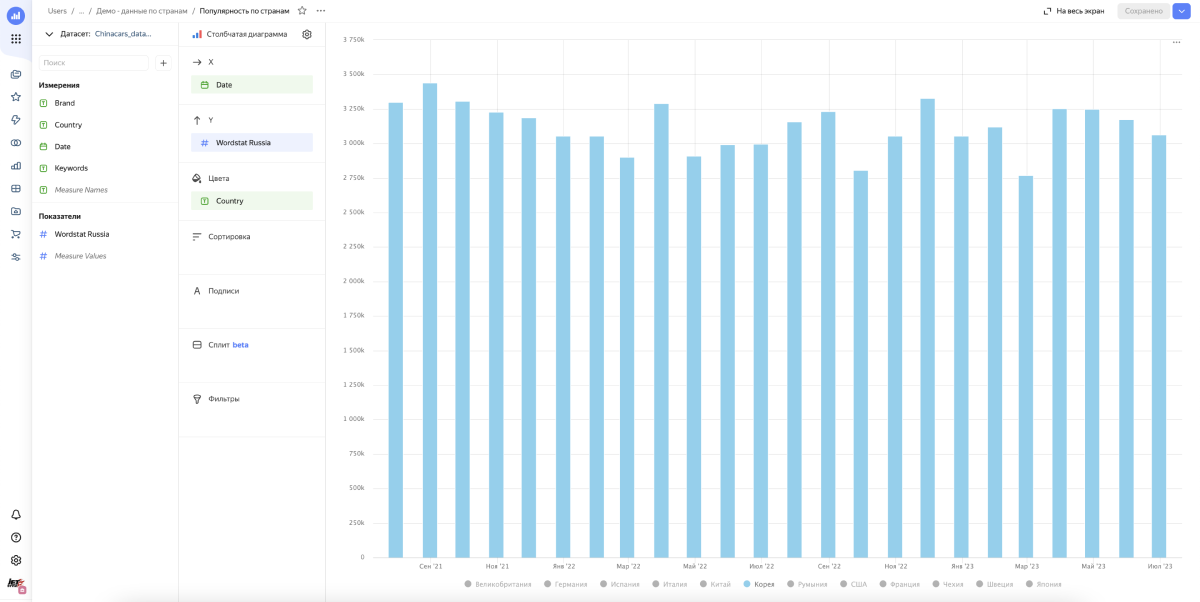
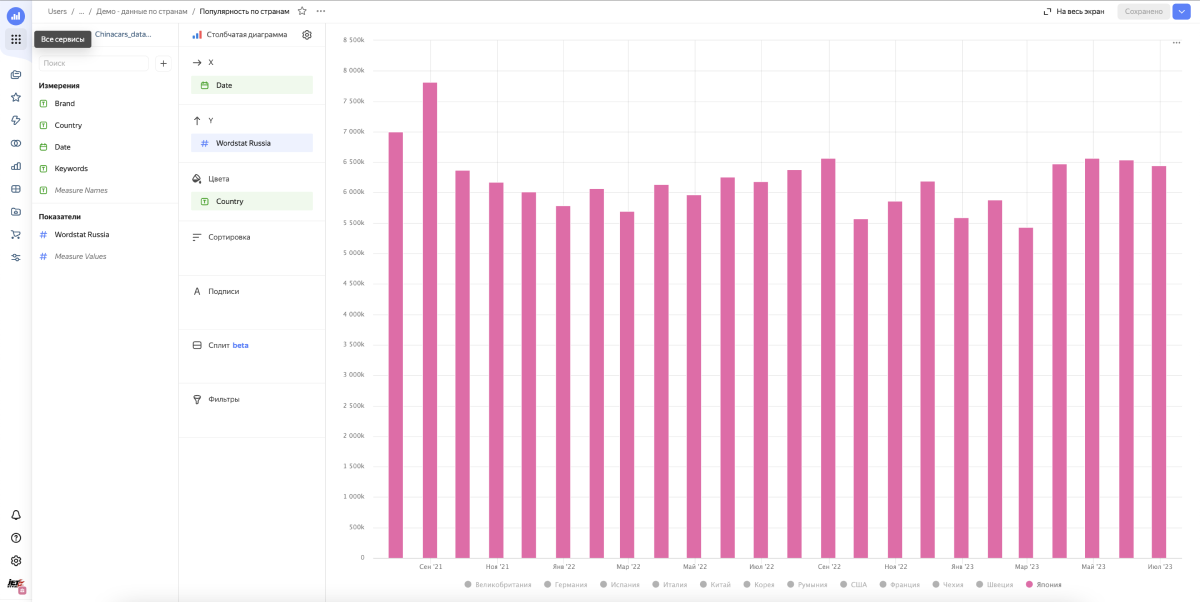
Интент — это цель, которую стремится достичь пользователь при поиске. Как правило, это дополнительное слово или группа слов, которое все уточняет. Например «купить», «ремонт» и другие целевые активности.
Как анализировать интенты — смотрите в ролике от Ahrefs:
Второй подход
1. Собираем список брендов и синонимов
Здесь все то же самое, что и в стандартном подходе.
2. Собираем список интентов
За определением интентов мы пошли в SpyWords (кстати, он доступен бесплатно, если у вас есть тариф «Оптимум» в Elama). Здесь можно посмотреть, по каким группам фраз в поиске находятся официальные сайты брендов.
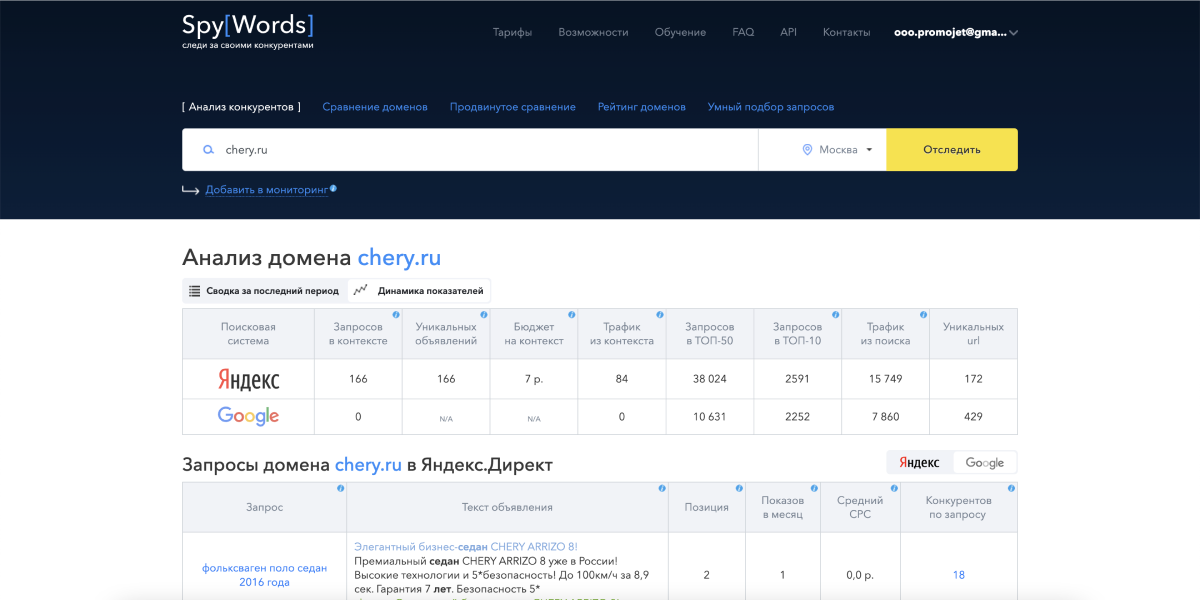
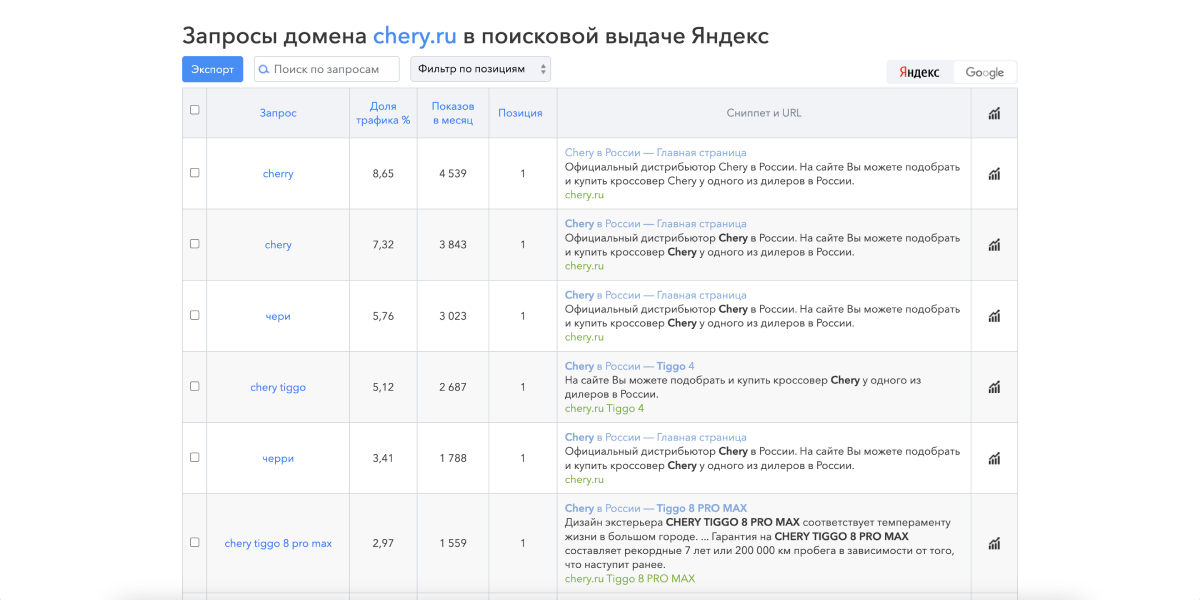
Tip: эту же задачу можно решить еще с помощью сервиса Разбивака от Алексея Кулакова.
Так мы получили список поисковых интентов:
- официальный сайт,
- официальный дилер,
- модельный ряд,
- комплектации,
- цена,
- купить,
- кредит,
- лизинг,
- рассрочка,
- отзывы,
- обзор,
- тест-драйв,
- сервис.
3. Перемножаем два списка поэлементно
Чтобы получить «оценку сверху» по всем кластерам запросов для каждого бренда, нам нужно было добавить интенты к списку всех брендов.
Это можно сделать вручную или автоматически. Подробности — в нашей статье на Хабре.
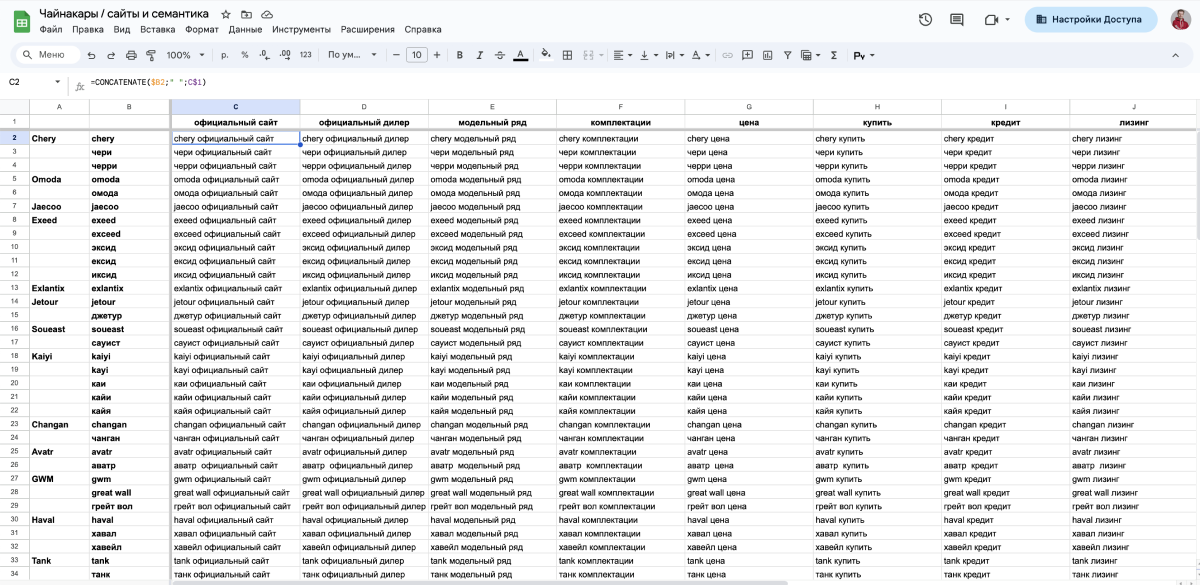
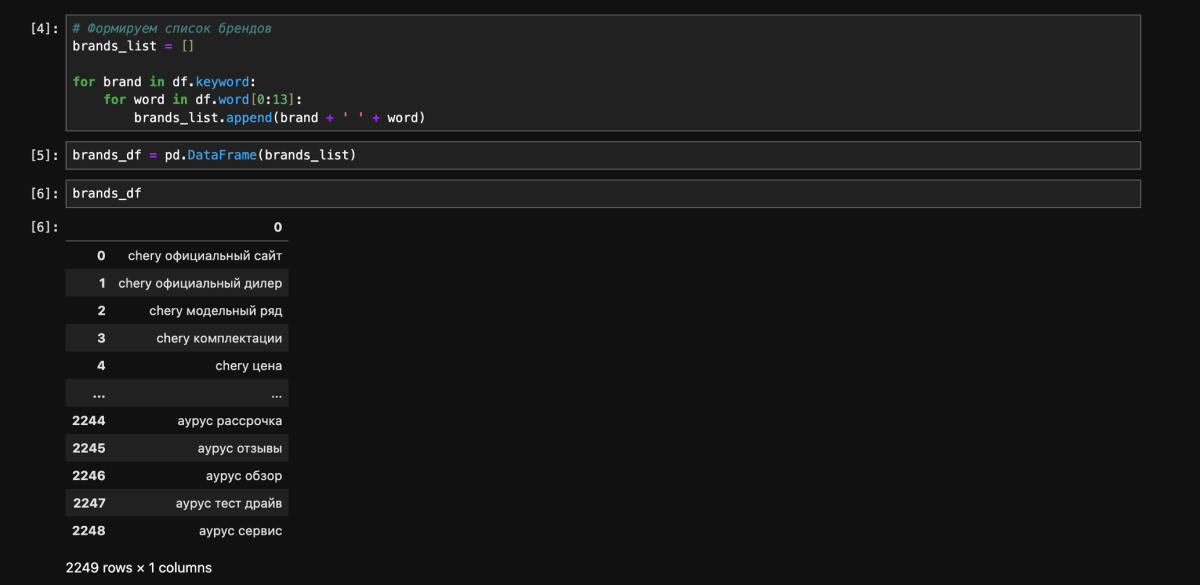
4. Получаем примерную семантику
Вместо 100+ запросов, у нас получилось 2000+ запросов без лишнего сбора и кластеризации семантики.
5. Собираем частоты и сезонности
Мы загрузили запросы в KeyCollector и запустили парсинг сезонности. На сбор данных ушло примерно 4–5 часов.
Дополнительно для удобства мы разложили все фразы на группы — при выгрузке группа добавляется в отдельную колонку, что позволяет объединить словоформы в группы по брендам. Эту же задачу можно решить при обработке на Python — примеры дальше.
На выходе мы получили CSV-файл со списком запросов и популярностью по месяцам — как и в первый раз, но кратно больше.
6. Обрабатываем данные
Ручная предобработка данных заняла бы очень много времени, поэтому мы снова воспользовались Python. Подробности — на Хабре.
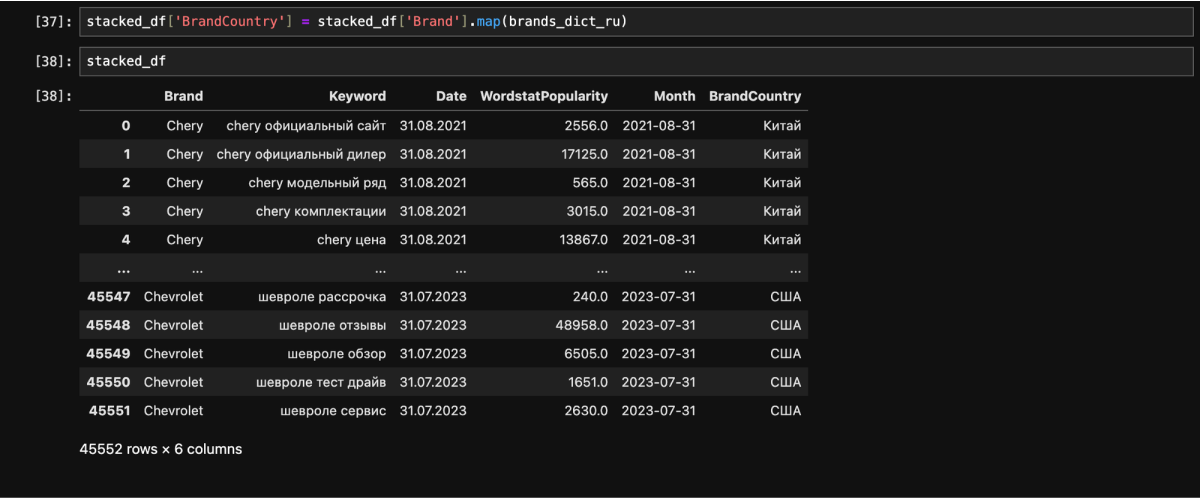
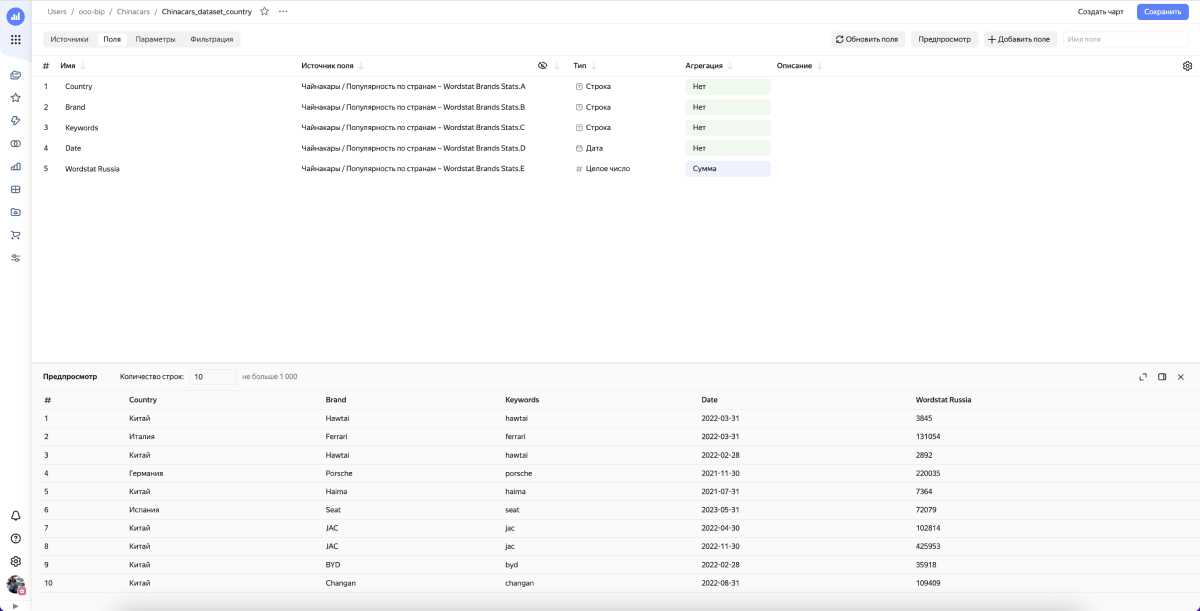
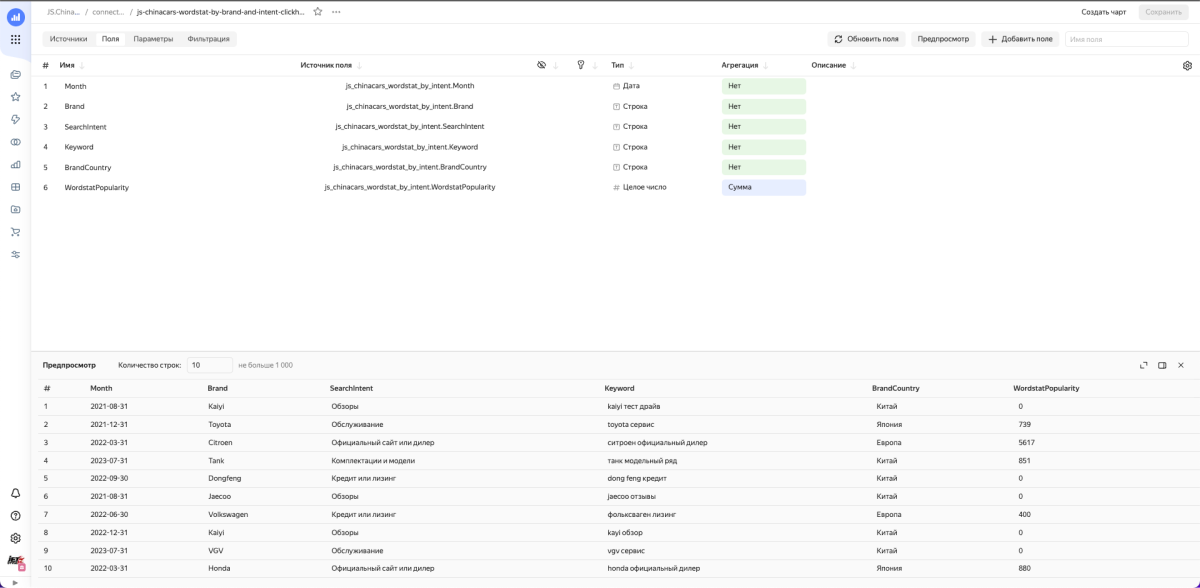
В результате у нас получилась таблица со следующими параметрами:

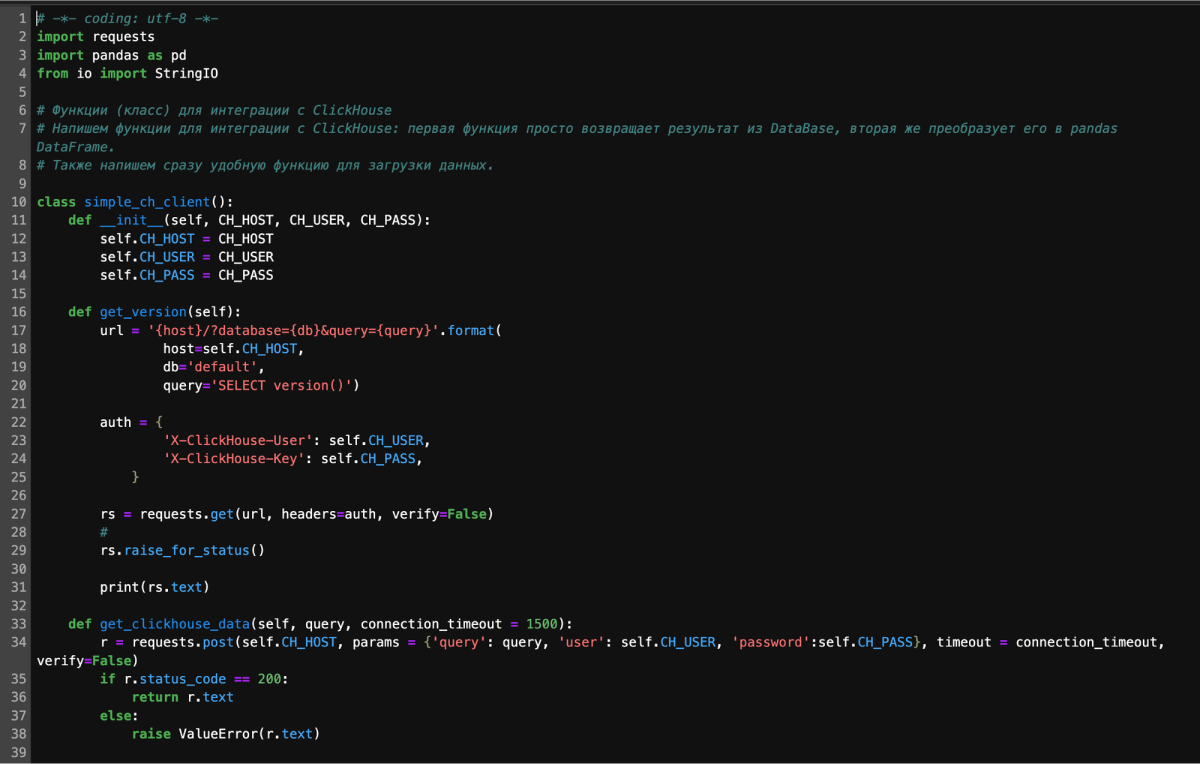
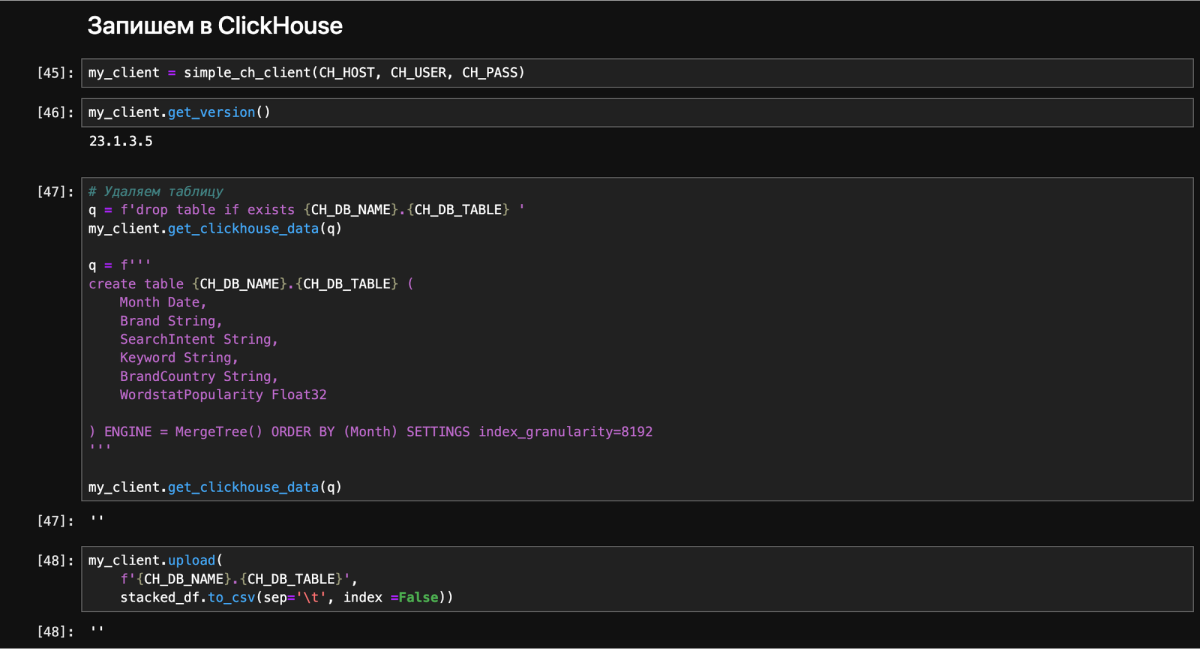
7. Выгружаем данные в ClickHouse
Подключились к базе, создали таблицу и записали туда наш DataFrame.
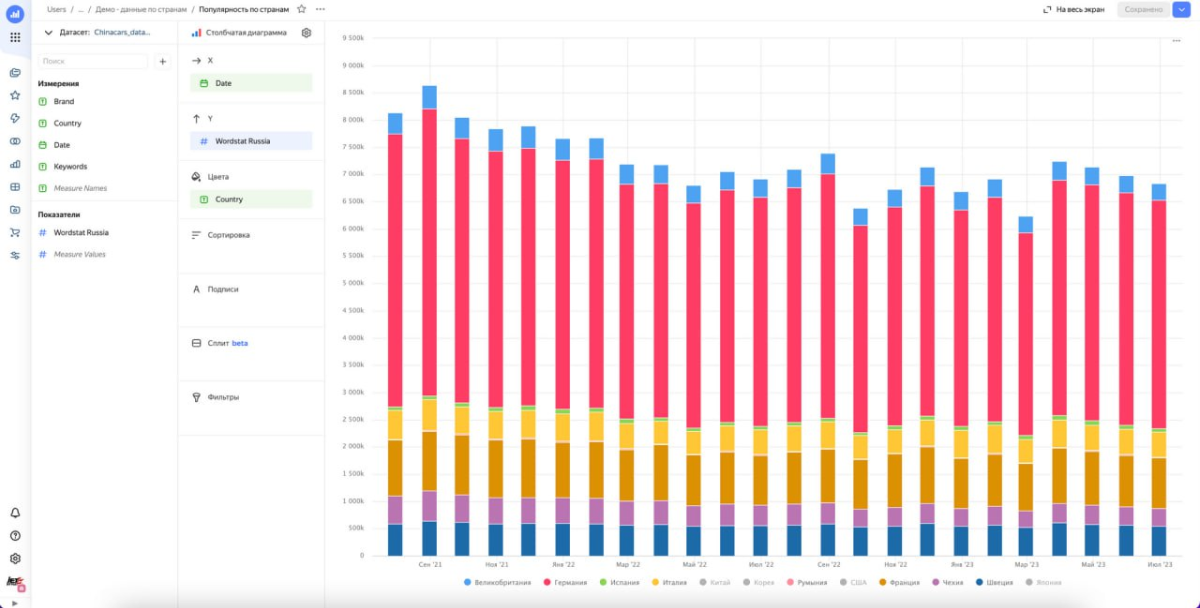
8. Строим чарты
Используя Data Lens, мы подключились к нашей базе и построили необходимые чарты.
Плюсы продвинутого подхода
Благодаря работе с интентами мы смогли в условиях небольшого ресурса собрать репрезентативную аналитику со спросом на автомобильном рынке, его динамикой, в разрезе по брендам, странам и другим переменным.
P. S. Дата-аналитикам на заметку: список инструментов
- KeyCollector — с его помощью можно легко и быстро собирать запросы и сезонности. К нему нужен аккаунт Яндекс Директ и proxy.
- Google-таблицы: в них можно складывать результаты и визуализировать с помощью простеньких графиков. А еще их можно подключить к DataLens, но есть нюансы.
- Python и библиотека Pandas — автоматизируют рутинные задачи по преобразованию собранных из Вордстата данных.
- ClickHouse — место, куда можно удобно сложить датасет. Можно остаться и в Google-таблицах, но ClickHouse надежнее и с заделом на будущее.
- Yandex Data Lens — BI-инструмент от Яндекса, в котором можно построить продвинутую визуализацию данных.
Экспериментируйте с аналитикой — как показывает наш пример, с помощью довольно простого набора инструментов можно решить объемную задачу достаточно быстро и качественно. А если хотите делегировать — приходите к нам в JetStyle. Вместе придумаем, как решить вашу задачу.







